源码文件导航
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
frameworks/native/services/surfaceflinger
SurfaceFlinger.cpp
main_surfaceflinger.cpp
MessageQueue.cpp
EventControlThread.cpp
DispSync.cpp
DisplayHardware/HWComposer.cpp
frameworks/native/libs/binder
ProcessState.cpp
system/core/libutils
Looper.cpp
frameworks/native/libs/gui/
DisplayEventReceiver.cpp
BitTube.cpp
|
概述
surfaceflinger是一个单独的进程,由init进程启动,是守护进程。设备开机boot过程会解析rc文件,并根据其配置启动系统服务
1
2
3
4
5
6
7
8
9
10
11
12
|
//service和四大组件中的service无关。会解析为启动阶段系统服务的对象,并启动
//指定服务名,执行文件位置
service surfaceflinger /system/bin/surfaceflinger
//核心class,表面启动时间是boot后就启动
class core
//用户 system,其它的还有root adb 等
user system
//用户组
group graphics drmrpc
//如果重启会导致zygote重启
onrestart restart zygote
writepid /dev/cpuset/system-background/tasks
|
启动
执行/system/bin/surfaceflinger,进入main方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
int main(int, char**) {
// When SF is launched in its own process, limit the number of
// binder threads to 4.
//self方法,获取ProcessState单例
ProcessState::self()->setThreadPoolMaxThreadCount(4);
// start the thread pool
//引用计数
sp<ProcessState> ps(ProcessState::self());
//启动binder 线程池
ps->startThreadPool();
// instantiate surfaceflinger
sp<SurfaceFlinger> flinger = new SurfaceFlinger();
//进程优先级 URGENT 紧迫的
setpriority(PRIO_PROCESS, 0, PRIORITY_URGENT_DISPLAY);
//调度策略 前台
set_sched_policy(0, SP_FOREGROUND);
// initialize before clients can connect
flinger->init();
// publish surface flinger
sp<IServiceManager> sm(defaultServiceManager());
sm->addService(String16(SurfaceFlinger::getServiceName()), flinger, false);
// run in this thread
flinger->run();
return 0;
}
|
创建binder线程池,个数上限为4
启动surfaceFlinger,进程优先级高,调度策略前台,在当前主线程一直run
构造函数
1
2
3
4
|
//最终继承到RefBase,主要是引用计数的,智能指针,引用为0后会回收
SurfaceFlinger:BnSurfaceComposer:BnInterface:ISurfaceComposer,BBinder:IBinder:RefBase
//binder通信接口定义,用于访问surfaceFlinger的方法
ISurfaceComposer:IInterface:RefBase
|
构造函数主要初始化一些调试开关
初始化
sp强引用指针,第一次被引用回调 onFirstRef方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
void SurfaceFlinger::onFirstRef()
{
mEventQueue.init(this);
}
void MessageQueue::init(const sp<SurfaceFlinger>& flinger)
{
mFlinger = flinger;
mLooper = new Looper(true);
mHandler = new Handler(*this);
}
class MessageQueue {
class Handler : public MessageHandler {
enum {
eventMaskInvalidate = 0x1,
eventMaskRefresh = 0x2,
eventMaskTransaction = 0x4
};
MessageQueue& mQueue;
int32_t mEventMask;
public:
Handler(MessageQueue& queue) : mQueue(queue), mEventMask(0) { }
virtual void handleMessage(const Message& message);
void dispatchRefresh();
void dispatchInvalidate();
void dispatchTransaction();
};
}
|
Looper.cpp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
//SurfaceFlinger.cpp
void SurfaceFlinger::run() {
do {
waitForEvent();
} while (true);
}
void SurfaceFlinger::waitForEvent() {
mEventQueue.waitMessage();
}
//MessageQueue.cpp
void MessageQueue::waitMessage() {
do {
IPCThreadState::self()->flushCommands();
int32_t ret = mLooper->pollOnce(-1);
switch (ret) {
case Looper::POLL_WAKE:
case Looper::POLL_CALLBACK:
continue;
case Looper::POLL_ERROR:
ALOGE("Looper::POLL_ERROR");
case Looper::POLL_TIMEOUT:
// timeout (should not happen)
continue;
default:
// should not happen
ALOGE("Looper::pollOnce() returned unknown status %d", ret);
continue;
}
} while (true);
}
|
pollOnce内部使用epoll机制,一种IO多路复用机制,fd可用后会进行回调,类似观察者模式
总结
Vsync
问题
- 为什么需要垂直同步
- 双缓冲就可以解决画面撕裂问题吗
- android4.1之前没有垂直同步吗?android4.1之后到底改了什么
- 为什么要三缓存
几个概念
逐行扫描: 屏幕显示是一行一行扫描显示的,并不是瞬间取走内存数据,瞬时显示,所以这个过程有时间。假如显示器完全显示完,然后刷新屏幕显示的帧缓存区,就不会出现屏幕撕裂的问题。如果显示到一半,这时帧缓冲刷新了,那么后半部分屏幕就会显示下一帧。
屏幕刷新率(HZ): 代表屏幕在一秒内刷新屏幕的次数,Android手机一般为60HZ(也就是1秒刷新60帧,大约16.67毫秒刷新1帧)
系统帧速率(FPS): 这个不是恒定的,应该可以说是一段时间的帧速率。代表了系统在一秒内合成的帧数,该值的大小由系统算法和硬件决定。
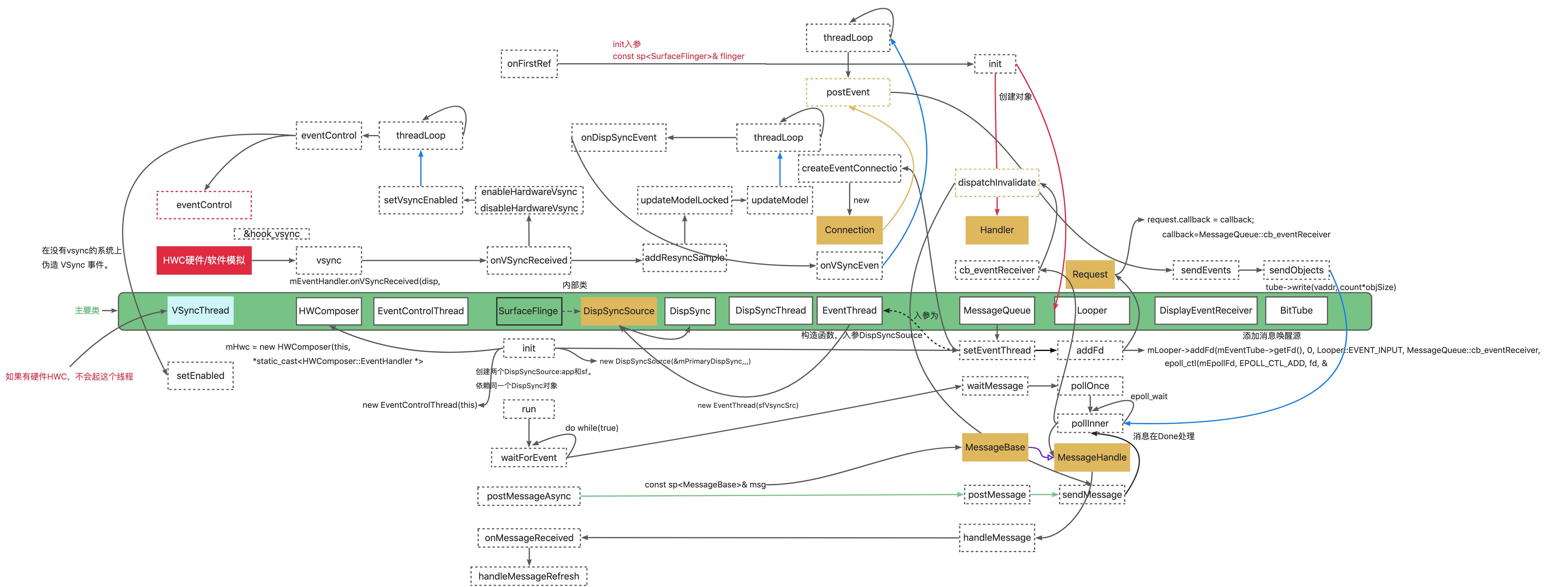
刷新率和帧速率不同步,导致画面出现一些问题,分两种情况讨论
- 屏幕刷新速率比系统帧速率快
屏幕已经显示完一帧画面,这时下一帧还未准备好,屏幕继续显示上一帧,出现一帧显示多次的情况,导致卡顿。
- 系统帧速率比屏幕刷新率快
屏幕正在显示一帧画面,此时下一帧已经好了,并且这时就进行了前后缓存交换,屏幕继续读取数据,这时画面就产生撕裂。
从上面分析可知,不管单缓冲还是双缓冲,都有可能出现撕裂问题,本质上是需要同步。单缓冲要是加锁也可以解决撕裂问题,但是这样GPU就会被挂起不能有效利用(显示的内存被显示器占用,GPU不能向里面写数据),所以这里要注意双缓冲指的是GPU的双缓冲。CPU画面处理的内存还是可以正常使用的,不会影响CPU。
垂直同步(VSync): 当屏幕从缓冲区扫描完一帧到屏幕上之后,开始扫描下一帧之前,发出的一个同步信号,该信号用来切换前缓冲区和后缓冲区。
垂直同步保证系统配合屏幕显示,需要固定时间准备好下一帧,屏幕显示时间一般固定,所以帧率基本稳定。所以垂直同步必须要双缓冲,假如单缓冲,同步信号没来,该缓存不能写入,GPU就挂起不工作了。
Android4.1之前:在Android4.1之前,屏幕刷新也遵循双缓存+VSync机制。Android4.1之后,系统绘制的优先级被提高,VSync来了同时就进行绘制操作(Draw)。
VSync来时才进行绘制会导致如下的问题
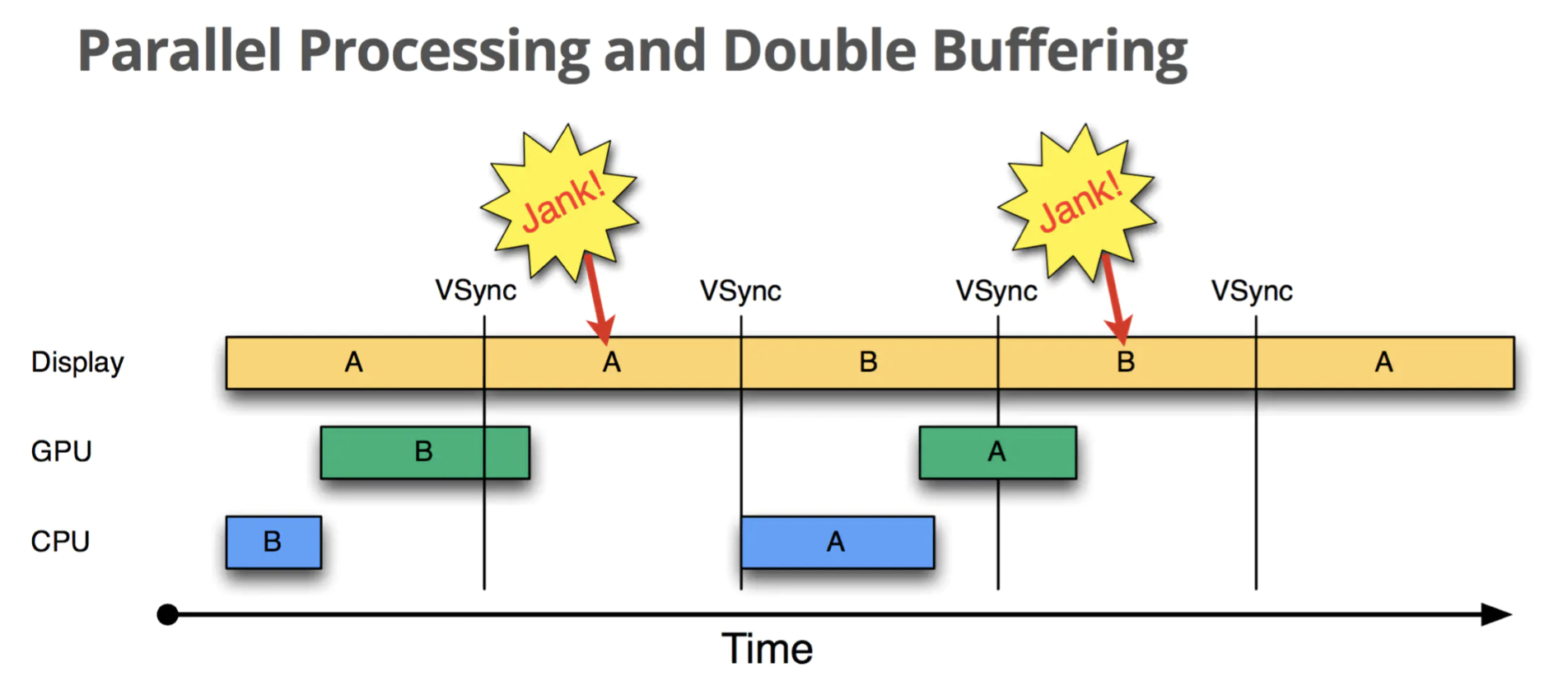 第一个Jank产生,B帧由于没有绘制完,继续显示A帧,这时由于VSync没来,GPU不进行下帧的绘制,等到VSync来了才绘制,这时由于绘制时长一直很长,那么就会一直Jank。问题产生原因是Vsync之间的时间被浪费掉了。相比没有改动前Jank情况更加严重。所以引入三缓冲,解决同步Drawing引入的GPU未充分使用问题。
第一个Jank产生,B帧由于没有绘制完,继续显示A帧,这时由于VSync没来,GPU不进行下帧的绘制,等到VSync来了才绘制,这时由于绘制时长一直很长,那么就会一直Jank。问题产生原因是Vsync之间的时间被浪费掉了。相比没有改动前Jank情况更加严重。所以引入三缓冲,解决同步Drawing引入的GPU未充分使用问题。
三缓冲情况如下
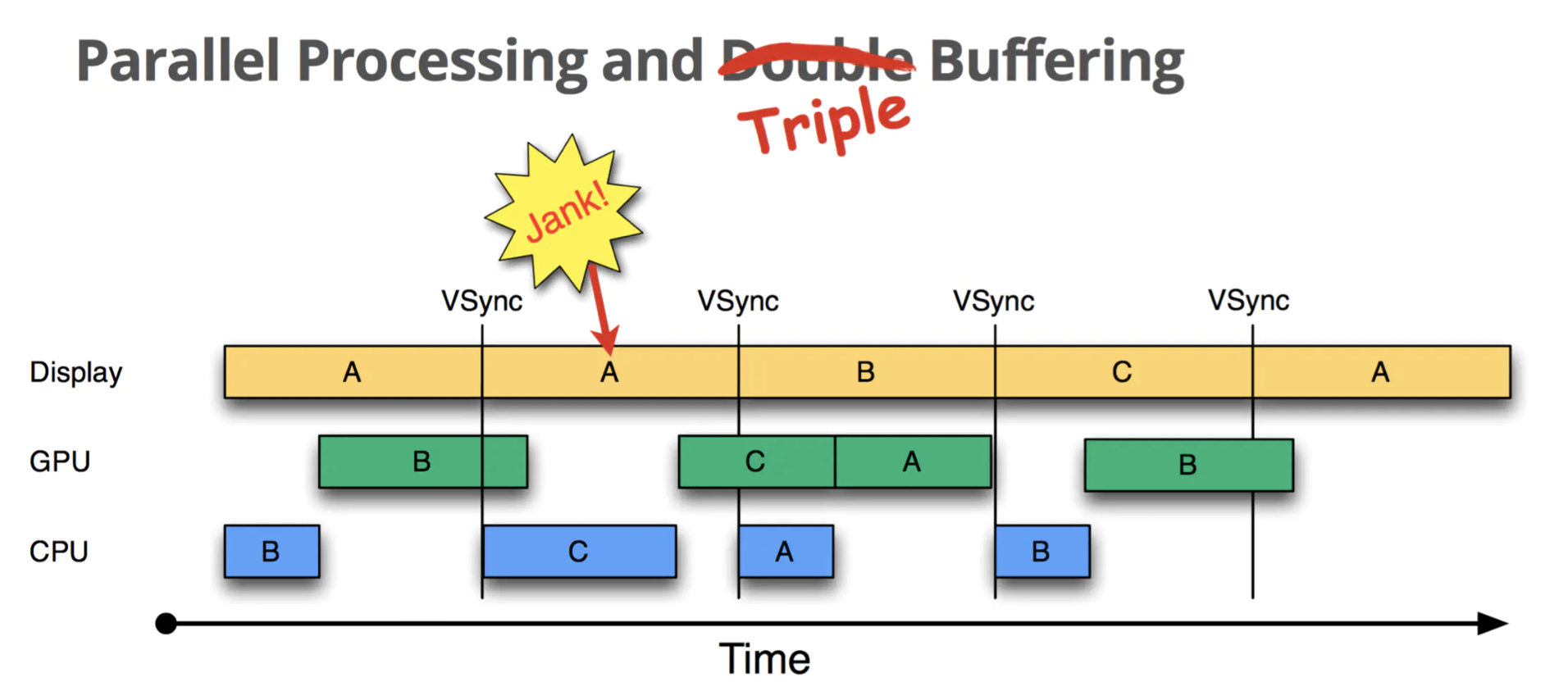 三缓冲有效利用了等待Vsync的时间,减少了Jank,但是带来了延迟。所以,Buffer正常情况下还是两个,当出现Jank后出现三个,三个已经足够使用。
三缓冲有效利用了等待Vsync的时间,减少了Jank,但是带来了延迟。所以,Buffer正常情况下还是两个,当出现Jank后出现三个,三个已经足够使用。
比较好的解释:https://developer.aliyun.com/article/952540
补充
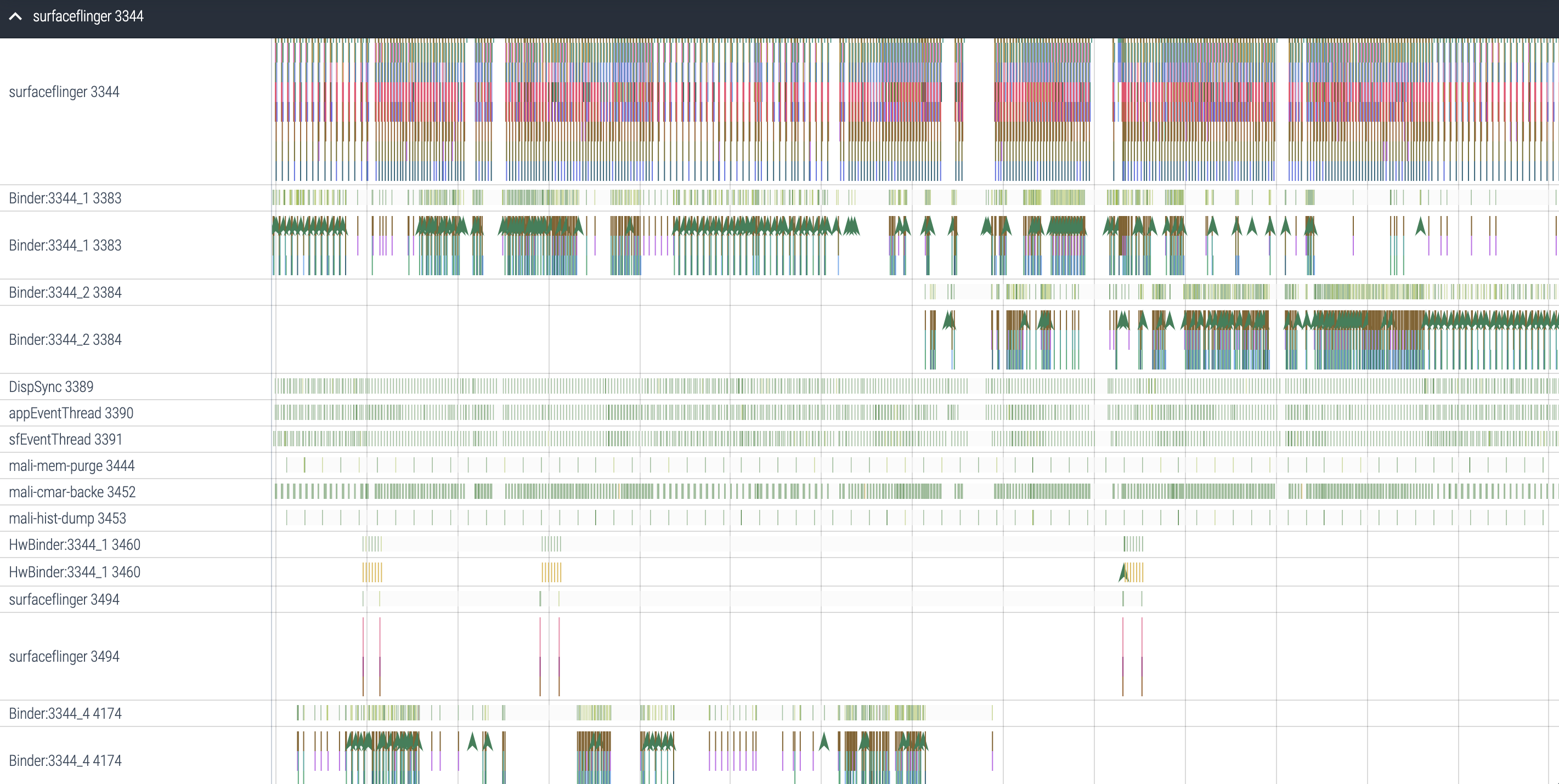 从systrace可以验证 binder线程池有4个线程,有熟悉的DispSync、EventThread。HwBinder和硬件进行交互。
从systrace可以验证 binder线程池有4个线程,有熟悉的DispSync、EventThread。HwBinder和硬件进行交互。
mali 和GPU相关,ARM Mali GPU系列知识参考
作为业界顶级芯片厂商,ARM能为各类便携式智能设备以及其他相关产品提供包括CPU、GPU在内的多方面的解决方案,其中ARM的GPU就是Mali系列,它既有世界上最小的符合OpenGL ES 1.1的GPU,也有支持全高清解码、或者具有可扩展性的多核解决方案,为高端数字娱乐系统提供强劲的支持。
1.仅针对图形的解决方案是基于 Utgard 架构的,可以在最小的芯片面积中获得最高的性能。基于可扩展的Utgard架构的产品包括Mali-300、Mali-400 MP以及Mali-450 MP。这些产品为大众市场提供了从低端到高端的各种可扩展的解决方案,为智能电视、平板电脑和智能手机提供了行业领先的图形性能。
Mali-400 MP是世界上第一个符合 OpenGL® ES 2.0标准的多核 GPU,具备可扩展的、最高可以支持到 1080 像素的分辨率二维和三维加速性能,同时保持 ARM在功耗和带宽效率方面的领先地位。Mali-450 MP将成功的图形产品系列的 OpenGL® ES 2.0 性能提高了一倍。通过扩展到最多 8 个内核,从而扩展了性能范围,并使处理吞吐量峰值提高了一倍。
 次阅读
次阅读